《点石成金》的棒球故事
无论在图书还是同名电影中,《点石成金》的故事所引发的数据挖掘方法的革命,改变了职业棒球运动。表面看来,《点石成金》这部电影讲述的是奥克兰竞技的总经理比利·比恩(Billy Beane)的故事,他找到了一个诀窍,并率领他资金短缺的俱乐部战胜了薪酬远高于其队员的球队。比恩用数据对其他人觉得从直觉、经验和日常训练中总结的“众所周知”的做法发起了挑战。他首创了一种方法,来识别球队可以支付得起薪酬的优秀运动员,而在棒球精英们传统的数据分析方法中,这些运动员则毫无价值。
这部电影在营销过程中被看做是竞技型影片。我一走进影院就立刻明白了《点石成金》最终说的是什么:数据挖掘技术成功的喜悦。在以这些数据被采集时从未设想过的方式来探究其意义方面,它是一个富有启发性的故事。比尔和他的同事对长久以来以击球率、全垒打和(打点中的)击球跑垒得分来衡量球员进攻价值的三位一体的数据体系发起了挑战,取而代之的是基于相同数据的新策略。他们摒弃了棒球作家及历史学家比尔·詹姆斯(Bill James)于20世纪70年代提出的理论,他认为传统的数据分析方法实际上是不完善的。詹姆斯的方法并不仅仅是一种直觉取代另一种的问题。他让比赛本身来决定哪种数据在预测进攻效果方面是最好的。
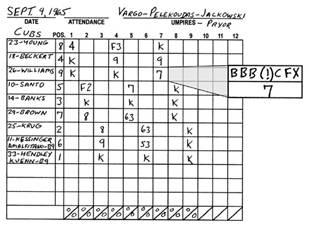
1965年,这一表格见证了小联盟球队的棒球投手山迪·柯法斯(Sandy Koufax)投出完全比赛,芝加哥队没有任何一名敌队球员到达一垒。记分牌显示柯法斯使击球员三击不中而出局(用K表示),而其他的腾空球落到了球场的右侧(用9表示)和左侧(用7表示)。但是一步一步的计分方式错过了这场比赛中比利威廉(Billy William)第七局围垦击球的关键时刻。虽然威廉最终打出了腾空球(用7表示),而每次投球的计分方法表明在他回击(用C表示)、犯规(用F表示)以及击球(用X表示)之前,柯法斯开始投出了三个球(用B表示),一个球偏离了跑垒的击球员,并弄得一团糟
这种方法并非轻而易举。试图直接预测比赛的胜场数可能会混淆团队在投球和守球方面的进攻技巧。詹姆斯指出我们在整个赛季过程中都应该通过预测每个球队的总分来对进攻数据进行测试。这表明上垒率和多垒安打率要远远优于用在这个方面的任何个人进攻数据。詹姆斯和其他人设计出了更独立于当时情境的投球和守球的数据分析方法。
比恩所利用的新数据分析方法让人耳目一新,因为该方法击败了其他业内专家的聪明才智。他的方法是《点石成金》这部影片中最好的一幕。采用这个新的数据挖掘方法,比恩就一个其他评估人员都认为“还不错”的球员向他们发起了挑战。一个守门员和他遭遇过,并且对他的冲击能力大加赞赏。比恩却说:“如果他是一个这么好的击球运动员,那为什么他击球不好呢?”
换句话说,抛开专家的直觉,数据是不会撒谎的。
细菌的数据统计
在我看来,棒球运动的革命带来了产生球队大名单的“完全傻瓜指南”――一本采用基本的定量分析方法而不是根据数十年的经验和直觉来编制的,并且让我们可以有所收获的手册。同样的数据挖掘方法更应该适用于科学领域。对科学来说,海量的数据以及对数据分析的能力在过去的几年里变得唾手可得了。数据现在正稳步超越专家的直觉和科学家过去一直捍卫的“事实”。
比如,就我自己的研究领域――生物学――来说。每个生物学家都“明白”什么是物种――物种是一群可以成功地延续后代的生物体。生物学家长久以来都认为物种的界定方式代表着生态和进化的基本单位。
就进化微生物学(我本人的专业)来说,在密切相关的细菌中能识别出所有的生态学基本单位是特别重要的。我们特别需要把具有危险性的微生物从不具有危险性的微生物中区别出来,以及把有益的微生物从无益的微生物中区别出来。确实,我们想区别在各自群落中发挥独特生态作用的所有的细菌种群。
而说到棒球,细菌多样性的发现经历了一个从依赖专家主观判断到采用客观且通用的数据分析方法的转变。起初,细菌多样性的发现和划界问题需要对特殊的生物群有丰富的专业知识,还涉及到区别新陈代谢过程和化学过程差别的复杂方法。为了使分类学更加易于理解,数十年前细菌研究领域引进了这种“完全傻瓜指南”并作为该艰巨任务的补充,这样任何人都可以大幅度地利用可获得的分子技术来鉴别物种――比如,鉴别一定水平上所有DNA序列的相似性。
一个流行的通用标准(除了其他的标准之外)就是属于某一物种的某一有机物,它与该物种中其他有机物的基因相似度要至少达到99%。问题在于――就像棒球运动一样,击球率、全垒打和(打点中的)击球跑垒得分都是用来补充专家知识的――在微生物领域没有人测试过这种新的分子技术是否真的能用来识别那些最密切相关的物种。
不幸的是,微生物学当前基于DNA的完全傻瓜指南,以及之前的专家驱动的新陈代谢标准都导致了物种鉴别中毫无帮助的综合维度。比如,大肠杆菌的种类包含平静地生存于我们内脏中的菌种,也包括各种各样的侵袭我们肠壁的病原体,以及侵袭我们尿路的病原体。此外,为了识别环境中的大肠杆菌,我们建立的粪便性污染检测装备的检测结果显示,大肠杆菌的亲缘物种没有负面效应,它们通常在清澈的池塘中度过余生,同时对人类也没有什么伤害能力。而且大肠杆菌也不是孑然一身,在这个典型的已被识别出的物种中还有南斯拉夫种群:就像一个表面上统一的国家中隐藏着巨大的种族和宗教多样性一样,大肠杆菌(以及被识别出的物种)包含了众多不同层次的生态和基因多样性,而这种多样性则全部隶属于一个物种。
我们可以用棒球改善其数据分析的方法来解决上述混乱的状况。让竞赛本身――在我们的例子中就是让自然本身――来决定哪种数据分析方法最能预测我们最想要的结果。在微生物领域,其诀窍就是让细菌告诉我们什么样的DNA排序方法能最精确地识别那些在栖息地和生活方式上存在着巨大差别的细菌。两个团队,包括麻省理工学院的马丁珀兹(Martin Polz)团队和我们维斯利安大学和蒙大拿州立大学的团队,已经设计出了计算机算法,并用来专门鉴定正式认可的物种中不同栖息地类型的细菌群。该算法摒弃了专家认为的每个物种中应该有多少多样性的标准。相反,他们分析了细菌进化的动力学,让有机物自己来告诉我们能最好地区分生态学上特定细菌中不同种群的DNA序列标准。
通过数据挖掘来发现生物群落的另外一个机遇源于新的人类微生物群系项目。这个项目从含有各种细菌的人类生活环境中采集DNA序列样本,比如内脏、口腔、皮肤和生殖器官,而这些样本则来自于具有不同年龄、性别、健康状况、体重和饮食习惯的个体。
比如,法国国家农业研究院的达斯科埃利克(Dusko Ehrlich)以及他的同事近期对从欧洲六个国家的39个人的粪便中净化出的基因进行了分析,而每个人的细菌中的DNA基数大约为1亿个。他们试图识别与年龄和体重相关的细菌生物化学函数。虽然他们的直觉促使他们提出了识别这些基因的各种猜测,且这种猜测得到了广泛的支持,但是用基于数据处理的方法来鉴别基因表明了生物化学函数与年龄和体重有更强的关联性。一个基于数据处理的重要发现表明在肥胖和微生物获取能量的能力之间是负相关的。
正在进行的大量关于人类、海洋生物以及土壤环境的基因测序项目使我们可以阐述细菌的多元化:来发现当前最新的变异细菌物种,来描述高度分化的不同栖息地的特征以及来鉴别每个栖息地中最重要的生物化学函数。然而,这个方法主要依赖于我们如何描述所抽取的栖息地样本。
词汇挖掘
除了微生物学领域,数据挖掘方式的变革还扩展到了自然科学和社会科学领域(气象学和经济学有长达数十年的大量数据,它们实际上称得上是这种方法的老祖宗)。在社会科学领域,特别有意思的是可以发现数据挖掘方法如何帮助语言学家分析书面语和口语中的词汇用法――比如,编制词典这个具有挑战性的工作。按传统,对语言用法的分析涉及书面语篇的评估,而这些用法通常来源于经典图书,且被专家认为是“惯用法”范本,其中一个阶段就是需要大量的志愿者把这些来源于经典图书的范本提供给词典编辑人员。然后被任命的一组语言专家对这些新用法做出主观判断――哪些是可以接受的,哪些是中庸的以及哪些是粗俗的。语言学上的数据革命使得我们摆脱了需要大量志愿者的境况,也摆脱了博学多才专家意见的影响。语言分析正在朝着制作完全傻瓜指南的方向前进,而这个指南基于实际使用的书面语和口语来决定可接受的用法。
各种书面语和口语的语料库出现在了网络上,这使得可以对这些词汇如何应用以及用在何处进行广泛分析。人们可以搜索并分析上传到网络上的整个语料库文本。其中最大的就是牛津语料库,该语料库开办于2006年并且覆盖了整个英联邦国家(以英语为主要语言的国家群体)的文本。以美国为中心的美国当代英语语料库(COCA)开办了一个以用户友好型为特色的网站(http://corpus.byu.edu/coca/)。在搜素某个词汇的时候,这个语料库会提供10个与被搜索词汇相关的用法,这会产生更多的信息。比如,一个搜索者可以看到这个词是用单数还是用复数,以及与这个词一起搭配的词汇等等。在《潮湿的鱿鱼》这本书中,杰里米?q巴特菲尔德(Jeremy Butterfield)描述了这些语料库在实际应用中何以会产生一副英语(或潜在的任何语言)的图景,并被整个作家和演说家群体所认可。
基于语料库的分析在竭力反对专家意见方面的一个方式,就是单凭通常被认可的标准就可以决定某一个逐渐演变的用法能否被接受。比如,“criteria(标准)”这个词刚从希腊语传入英语的时候还保留着其原来的意思,即作为“criterion”这个词的复数形式。虽然我们会感到尴尬,但是我们自身的经验加之对牛津语料库的分析表明“criteria”这个词单数形式的使用频率赶上了这个词复数形式的使用频率。该语料库还让我们注意到当前那些对我们仍有意义的古老表达方式的变迁,只是我们需要对这个词汇稍作调整。莎士比亚的名言“刹那间(in one fell swoop)”在四个世纪后的今天仍然十分流行,但是我们需要把这个已经过时的形容词“fell”变成一个和它发音类似且意义相近的词,即“foul”。虽然专家们很不情愿,但是语言确实在不断演化,而语料库则允许我们确认这种变化的有效性。
拘泥于过去的信息
完全傻瓜指南这个有用的方法已经应用于不同领域,不过这给从陈旧的数据挖掘新意带来了严峻的挑战。其困难在于当事情发生的时候,数据采集人员并没有考虑到这些数据将以他们想不到的方式进行分析。比如在棒球比赛、生态学和语言学这些案例中,有时候遗漏了一些重要数据,而有时候又胡子眉毛一把抓。这是利用过去数据导致的一个双胞胎问题,这个问题也是社群主义的挑战――既然我们意识到所采集的数据通常都被以采集时所没想到的方式利用,那么我们应该如何确保记录今天的数据在未来更有价值呢?
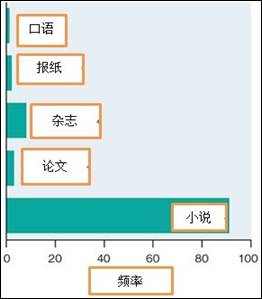
通过搜素美国当代英语语料库,可以发现短语“她喘着粗气(she drew her breath)”及其变体(he drew his breath, she draws her breath, draws breath, draw breath, drew breath等等)在文学作品和其他书面语中的使用频率要远远超过其在口头语中的频率。这些例子表明在没有录音手段之前,小说和故事中的对话在分析英语书面语如何随着时间的推移而变迁方面可能是个反面教材
棒球和科学在从旧数据挖掘中寻找新突破方面有着共性,而事实也证明以往的数据库对于我们发现棒球或者科学的新“规律”来说已经足够了。然而在太多的案例中,对陈旧数据重新进行的检查表明我们尽力忽略的一些数据已经使科学失去了一次进步的机会。
回首往事,我惊讶于棒球和生态学对未来的数据挖掘工作几乎毫无兴趣。在棒球运动中,传统的一步一步的记录方式一统天下的局面在1988年以前一直都是备受信赖的,而之后每次投球的记录方法成为了标准。新的记录方法在很多方面都是重要的――比如,在控制投手的生命力、健康和寿命方面。
直到最近,生态学在数据采集方面还存在着短视行为;这给想对其他科学家发表的数据进行分析的生态学家带来了问题。比如,科罗拉多大学的凯西·洛祖波内(Cathy Lozupone)和罗布·奈特(Rob Knight)通过分析其他数据认为在细菌的演变历史过程中,最困难的进化演变莫过于从含盐的环境到无盐环境,反过来也是一样的。然而,因为起初的研究人员并没有记录实际的盐分水平,所以洛祖波内和奈特不能精确地算出那最难以逾越的盐浓度。
生态学上以前的数据采集标准是仅仅局限于手头实验或者同一个实验室未来实验可能感兴趣的数据。而今天,生态学家越来越期望我们采集的数据被其他人所使用,并尽心竭力地这样去做,但是实现起来并非易事。
我最近遇到了希尔玛·拉普(Hilmar Lapp),他是国家进化综合中心(NESCent)的数据库专家,我们探讨了研究人员如何在采集数据时避免遗漏重要因素。他说就生态学而言,我们不要期望任何一个研究人员认为他自己采集到了所有后人认为值得采集的数据;他认为我们需要发挥“集体智慧”。相应地,国家进化综合中心和其他组织还是倡议成立工作组来汇集想法,并提出生态学在新研究领域采集数据的标准和方向――也就是说,鼓励发挥集体智慧。比如,基因组测序协会最近在抽取基因和整套基因序列样本时,建立了环境数据采集方面的标准;如果早期就采取这样的行动,那么洛祖波内和奈特就可能避免因缺少盐度数据而失落的局面。
有时候,我们没有关于过去事件的数据,这并不是因为缺乏想象力,而是因为那时还没有可利用的恰当技术。就棒球来说,新的高科技高级测量指标(AVM)体系自动记录了每次击球的轨迹、速度和落地点。该指标对每次击球的记录有助于分析守场员接住一个通常以双杀而告终的球的频率。但是在这项技术出现之前,没有人能在这一层次上分析守场员的技能。
即使在当前的生态学领域,微生物技术的缺乏还限制着植物生态学家了解那些有助于某一特定植物物种生长的因素。直到最近,植物生态学家才发现很多植物物种的成功存续实质上是由土壤中有益和有害微生物共同作用决定的。因而,由于在采集土壤微生物数据方面的不足,使得试图发现某一植物物种成功和失败的数十年的潜心研究显得漏洞百出。
而在语言学上,录音技术的缺失也长时间地阻碍了对英语口语用法的分析。你也许认为小说和故事中的书面对话可能是实际录音的代用品;这些对话通常和我们录下来的一样。但是,让人沮丧的是,词典学者兼作家的奥林哈格雷弗斯(Orin Hargraves)通过对语料库和小说中词汇用法的比较分析发现:实际上那些类似于口语的陈词滥调出现在文学作品的频率要大大超过其用在日常生活的频率。比如,很少有人说“他直挺挺地站在那里(he bolted upright)”或者“他喘着粗气(she drew her breath)”,但是这些用法在文学作品中却屡见不鲜。进而,在20世纪,人们开始采用了一种无偏见的、基于语料库的方法收集大量的英语口语录音材料。
分析大量的数据使得我们可以超越以前的想法,过去的工作所依赖的数据要比我们今天少得多。对今天和未来的探索者来说,通过数据分析来理解比赛、生物和词汇,可以为我们提供无限可能。我们应该为未来的探索者提供我们当今生活最好也最全面的生活记录。
《点石成金》这部影片以米基曼托尔的名言开头:“让人难以置信的是,你对一辈子都在从事的比赛却知之甚少。”同样这句话也适用于自然科学和社会科学领域。
资料来源 American Scientist
责任编辑 李 辉