继科学家完成人类基因组测序工作后,现在已步入深入研究的阶段。没有人知道人类基因组里究竟藏有多少信息,也不知道什么时候才能停下寻找的步伐?但你可以想像,真正理解并掌握基因组将成为本世纪或下世纪的一项重中之重的大科学工程。
在过去的五年中,欧洲分子生物学实验室(EMBL)的计算生物学家尤恩·伯尼(Ewan Birney)和同事们为“DNA元件百科全书计划”(Encyclopedia of DNA Elements,ENCODE)收集了大量的基因组数据,最近他准备把这些数据打印出来。然而,要找个可以放置这份打印文件的地方可不容易,即便每平方厘米能容纳1 000对碱基,但文件还是高达16米,至少30公里长。
ENCODE:志在“荒漠”垦荒
当人类基因组计划完成之后,尽管科学家为揭示人类生物学蓝图作出了巨大的努力,但很快便意识到,读取这份蓝图的“操作手册”还很粗略。研究人员可以确定,30亿对碱基中有很多蛋白质编码区(大约2万个基因),仅占整个基因组的不到1%,这仅仅是在一大片未知领域中识别出一些稍稍熟悉一点的对象而已。很多生物学家甚至怀疑,真正体现人类遗传的完美和复杂性的精华部分,可能正隐藏在基因之间那些未探索的“荒漠”之中。于2003年启动的ENCODE计划,正是为探索这片“荒漠”而建立起的一个巨大的数据搜集工程,其目标是为潜伏在“荒漠”中的那些“功能性”基因序列编制目录,了解它们位于哪些细胞中、何时被激活,而基因组又是如何被合成、调节和读取的。
在最初的导入期之后,ENCODE计划的科学家们基于2007年获取的全部基因组测序结果,开始应用新的研究方法。目前,研究已经接近尾声,基于在《自然》、《基因组研究》和《基因组生物学》杂志公开发表的30篇论文,已经确认大约80%的基因组都具备某种特定功能,其中包括约7万个“启动子”区域(位于基因上游),负责蛋白质绑定并执行基因表达的位点;约40万个“增强子”,负责基因的调节和表达。
伯尼在ENCODE计划中负责协调数据分析,他表示ENCODE计划的工作远未完成。他说,一些绘制基因图谱的工作还在进行中,而对于基因组到底能做些什么及进一步的深度特性分析,才仅仅完成10%。而正在执行的第三阶段计划,将最终完成阅读人类基因的指导手册,并提供更多的细节描述。
许多人已经从人类基因库的巨大数据流中获益,并被其巨大的前景所鼓舞。ENCODE计划点亮了人类基因研究的黑暗角落,为进一步理解基因变异是如何影响人类的遗传缺陷和疾病而创造新的机遇。进一步探索项目中所揭示的神秘调节因子以及比对其他哺乳动物,一定会重塑人类关于自身进化的科学认知。
然而,到底哪里才算是尽头。英国牛津大学的计算生物学家克里斯·庞廷(Chris Ponting)说:“我没见过失控的火车会很快停下来。”虽然他是ENCODE计划的支持者,但也质疑其在某些方面的回报率,要知道,该计划的投资已超过1.85亿美元。来自马萨诸塞大学伍斯特医学院的ENCODE项目负责人约伯·德克(Job Dekker)说:“有时候,人们需要经历一段很长的时间,才知道自己究竟能从给定的数据中获取多少有益的信息。”
先导项目:初窥基因特性
即使在人类基因组测序计划终止之前,作为人类基因测序的主导者,美国国家人类基因组研究所(NHGRI)就开始对是否在计划中追求系统性的测定和标记DNA的功能序列上,存在过一些争议。2003年,NHGRI曾邀请许多生物学家并接纳其建议启动了一个先导项目,通过针对仅1%的基因组进行预研究,试图发现哪种实验性技术可以在最终的工作中表现的最好。
先导项目转变了生物学家对基因组的看法。即,事实上只有很少量的DNA参与制造蛋白质编码的信使RNA。例如,研究人员发现,只有一小部分DNA产生编码蛋白质的信使RNA,而大部分基因组都将被转录成为非编码的RNA分子(目前,已知其中一些非编码RNA分子在基因表达中起重要的调控作用)。尽管一些基因学家认为功能性组件是物种间最稳定的部分,但事实上许多重要的调节序列也处于快速进化过程中。
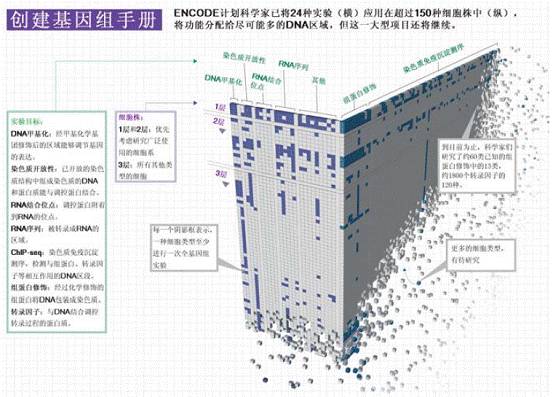
NHGRI为此发起了第二轮邀请。2007年,NHGRI在发布其第二轮科研需求之前公布了其研究结果,同时希望参与未来项目的研究人员将工作延伸至全部基因组。其时,恰逢新一代测序仪器的快速发展,数据采集变得更快速和廉价。西雅图华盛顿大学的ENCODE计划参与者约翰·斯塔玛托扬诺普洛斯(John Stamatoyannopoulos)说:“在预算没有增加的情况下,我们生成的数据是预计的5倍。”
32个小组、约440多名科学家致力于24个标准类型的实验。他们针对从基因组中转录而来的RNA进行分离和测序,确定了大约120个转录因子的DNA结合位点,将大约120种转录因子标定在DNA指定点位,同时绘制了被甲基化基团覆盖的基因组区域(位于被甲基化区域的基因通常处于沉默状态)。他们还检查了组蛋白的化学修饰模式。而这一模式可以将DNA组装为染色体,并激活基因的不同区域以促进或抑制转录过程。虽然基因组在绝大多数人类细胞中都一样的,但实际活动却往往大相径庭。因此科学家们针对至少147种不同的细胞类型进行实验,并导致ENCODE计划出现了1 648种不同的实验。
例如,斯塔玛托扬诺普洛斯小组用一种名为DNaseI的酶绘制了125种细胞的调节区域。这种酶对于和组蛋白相结合的DNA影响很小,但可用于分离与调节蛋白绑定的DNA,如转录因子。对于被分离DNA的测序工作表明,调节蛋白在不同的细胞中结合在不同位点。该小组总共发现了大约290万个位点,其中三分之一的点位只在一种细胞类型中被发现,只有3 00个位点在所有细胞中被发现,而这一点极大的表明基因组是如何通过在不同细胞类型中的调节作用而产生细胞间的显著差异。
当我们把许多数据集叠加到一起时,真正有趣的事出现了。比如,组蛋白修饰变化观测的实验表明,其模式与对DNaseI酶敏感区的边界完全一致。科学家还能进一步说明,究竟是哪一种转录因子在何时产生作用以及绑定到哪里。现已探明,原先广阔的“荒漠”区域蕴藏着成千上万与基因调节相关的特性,而且每种细胞类型都在使用这些调节功能的不同排列组合来产生其特有的生化功能。这一点有助于解释为何相对较少的蛋白质编码基因能够提供如此丰富和复杂的生物化学功能并支撑着人体的生长和活动。
正在领导部分数据分析工作的马萨诸塞州剑桥技术研究所的计算基因学家马诺里斯·克里斯(Manolis Kellis)说,ENCODE计划将包含“远远超出将基因各个部分简单叠加所得到的功能。”
填补空白:抑或路途漫漫
ENCODE计划目前产生的数据正在帮助研究人员进一步了解疾病遗传学。从2005年开始,全基因组相关研究(GWAS)已经发现了数以千计的可能致病基因,而其中仅仅一个碱基的不同或变异就会导致疾病的风险。由于大约90%的此类变异都不是蛋白质编码基因,科学家目前对于它们是如何导致疾病的发生还没有任何线索。
ENCODE绘制的基因图谱揭示,多数遗传基因的致病区域包括“增强子”或其他功能序列。而细胞类型也非常重要。目前,克里斯小组针对一些与系统性红斑狼疮高度相关的突变进行了研究,这种疾病往往导致患者的免疫系统主动攻击自体的正常组织。他们注意到,GWAS所发现的遗传变异倾向于分布在只有对免疫细胞才活跃的调节区域,但对其他类型的细胞并非如此,克里斯的博士后卢卡斯·沃德(Lucas Ward)为此构建了一个HaploReg网页,旨在让研究人员比对GWAS和ENCODE数据之间存在的不同之处,并以系统的方式进行处理和显示。克里斯说:“非常感谢ENCODE计划,可以针对如此复杂的遗传疾病发起攻势,我们现在能够解析更为复杂的病症。”
对于已有的ENCODE数据,研究人员还要花费很多年对其进行研究。而这还远远不是尽头。加州大学圣克鲁兹分校网站上展示出ENCODE计划的进展,其中一个表格显示了目前24种实验所获得的进展,差不多180种细胞类型已被测定。这只是九牛一毛,包括实验室里常用的HeLa和GM12878细胞研究的比较完整,可这仅仅是针对少数细胞系进行的检测。至于其他部分,也就仅仅完成了一次实验而已。
科学家们将在第三阶段的研究中来填补部分空白,而伯尼称此为“扩建”,即增加更多的实验手段和细胞类型,进一步扩展和使用类似的染色体免疫吸收剂(ChIP)新技术。而这一技术可以找到所有绑定至特定蛋白质的基因序列,包括转录因子和改良的组蛋白。经过努力,研究人员将一一为这些绑定蛋白质的DNA开发相关抗体,用这些抗体将蛋白质和任何相关DNA从细胞中分离出来,最后再为这些DNA测序。
伯尼说,至少一个迫在眉睫的难题是,即大家认为只有约2 000种类似的蛋白质需要分析(ENCODE计划已经拥有其中十分之一的样本)。更困难的是要弄清楚到底有多少种细胞系需要我们分析。迄今为止,大部分实验对象是针对一些适合在培养环境中生长的细胞系,它们虽然在实验室里生长迅速,但失去了自然的特性。
以细胞系GM12878为例,它源自于血液细胞,使用病毒驱动细胞并用来分裂复制,而组蛋白或其他因子则可能被非正常的绑定至极度活跃的基因中。而HeLa是50多年前从宫颈癌切片组织中培养得到的,并通过基因重组技术改良。伯尼在最近的一次谈话中打趣地说,它确实称得上是一个新物种。
尽头在哪:期待阶段性转折
目前,从事ENCODE计划的研究人员试图直接从人体内获得正常细胞。然而由于许多这类细胞难以在实验室环境中生存,与使用样本不同,实验不得不只针对少量DNA或诸如脑细胞组织进行。ENCODE计划的合作者们也在开始讨论进一步研究人与人之间的基因变异是如何影响基因组中调节组件的活动的。曾帮助设计ENCODE数据架构的耶鲁大学计算生物学家马克·格斯坦(Mark Gerstein)说:“在某些地方存在的一些序列变异,意味着这些转录因子不像它们在其他地方那样的绑定。”最终,研究人员可能研究几十个甚至上百个不同的样本。
实验的范围也在扩大。一个进展迅速的研究领域包括在三维空间上观察基因组不同部分之间的相互作用。如果插入DNA是一个链,那么增强子能够在远端调节成百上千对碱基――与增强子结合的蛋白质最终会与那些临近基因的序列发生相互作用。德克和同事们已经开发出绘制这种相互作用的技术。首先,用化学试剂将DNA结合蛋白融合在一起。然后将结合蛋白中的插入链和序列分离,从而揭示调节组件之间的距离联系。目前,他们正在进一步扩努力以探索基因组之间的相互作用。德科说:“这已超越了对基因组的简单描述,而进入下一个阶段。”
问题是,哪里才是尽头?克里斯认为,有些实验手段可能已趋近极致。如果数据获取速度仍然无法满足需求,我们将不得不放弃某些实验。他同时还表示,科学家们最终能积累足够的数据来预测那些尚未探索的基因序列及其功能。而这一过程是基因组科学长久以来的工作目标。克里斯说:“我认为将会有一个阶段性的转变,有时归纳比实际做实验更有效和更准确。”
然而,伴随着成千上万的细胞类型需要测试,实验技术也有待不断发展,项目看似在无休止地延长。“我们离大功告成还差很远,”亨茨维尔市哈德森阿尔法特生物技术研究所的遗传学家瑞克·迈尔斯(Rick Myers)说,“你可能认为该项目会永远持续下去。”这多少有点让人担心。ENCODE计划前期工作估计花费了5 500万美元,扩大规模后投入大约是1.3亿美元,NHGRI为下一阶段募集资金为1.23亿美元。
一些研究人员申辩称,目前他们还没有看到明确的回报。首先,很难收集正在被使用的ENCODE计划数据的详细信息。NHGRI项目程序负责人迈克·帕津(Mike Pazin),通过检索所有在ENCODE计划中发挥重要作用的论文,他统计约有300篇,其中110篇是来自没有得到ENCODE计划资助的实验室。不过,这项统计数据有些微妙,因为“ENCODE”这个词在遗传学和基因组学论文中出现的频率很高。帕津挖苦地说:“从自身找原因吧,下次得起个独一无二的名字。”
一些科学家抱怨说,近十年的工作没有太多的发现。也有人认为,为这个项目花费的资金还不如投向其他项目――比如,由研究人员自发的假设性探索课题。这种抱怨在人类基因组计划进行时也发生过,不过,基因组计划有明确的终点,而ENCODE计划还看不到尽头(本质上是无止境的)。
最后,格斯坦说,人类花费大约半个世纪才获知DNA是人类的遗传物质。进展到人类基因组功能测序,”你一定可以想像,真正理解并掌握基因组将成为本世纪或下世纪的一项重中之重的大科学工程。
资料来源 Nature
责任编辑 则 鸣