深度思维,这个曾创建了世界上最强大的人工智能围棋程序AlphaGo的公司,将注意力转向了国际象棋,并取得了颇为惊人的成果。

想象一下,你告诉一个计算机系统如何走棋,并告诉它要学会的下棋规则。一天之后――是的,仅仅24小时――它的水平已经达到了能够击败世界上当下最强大的程序!
深度思维公司与AlphaZero
大约3年前,谷歌旗下的一家专门从事人工智能开发的公司――深度思维(DeepMind)将注意力转向了围棋这一历史悠久的游戏。一直以来,人们都未能成功设计出世界级的人工智能围棋程序――甚至认为这是未来10年都无法实现的目标。但奇迹终于还是出现了。一场公开的挑战发起了――一位传奇的世界级围棋选手李世石与谷歌人工智能AlphaGo展开人机大战――每个人都认为这将是一场有趣的比赛,而且认为人类一定会赢。人们甚至觉得问题并不在于AlphaGo程序是赢或输,而在于其距离“圣杯”(指人工智能战胜人类)的目标又近了多少。结果是AlphaGo以4∶1取得压倒性的胜利,这是围棋世界的一场革命。尽管人们对这一结果发表了大量的评论,但最终他们还是接受了现实――AlphaGo是一台非常优秀的机器,但也并非不可战胜。毕竟,它还是输了一场比赛。
这一传奇故事并未就此结束。一年后,一个更新版本的AlphaGo对战世界围棋冠军柯洁――一个年轻的中国人,其在围棋方面的天赋可比拟马格努斯·卡尔森(Magnus Carlsen)在国际象棋领域的才能。柯洁在16岁的时候就赢得了世界级围棋比赛,17岁就成了世界围棋冠军。对战时,柯洁已经19岁,能力更强了。这场新的人机大战在中国举行,比赛前甚至连柯洁都知道自己很可能会惨败,已经不再抱任何幻想。他表现得非常出色,但仍然以0∶3的比分输掉了比赛,这足以有力地证明新型人工智能的惊人能力。
人工智能在围棋界表现如此惊人,使得许多国际象棋选手和权威人士都很想知道,人工智能在国际象棋比赛中会有怎样的表现。人们对其获胜的程度仍有很大疑虑。因为围棋是一个复杂而漫长的游戏,棋盘上有纵横各19条直线构成361个交叉点,棋子走在交叉点上,双方交替行棋,落子后不能移动,以围地多者为胜。预先计算是徒劳的,而模式识别才是最重要的。国际象棋则迥然不同。象棋中知识和模式识别是非常重要的,而且这种皇室游戏非常讲究战术――工于心计、精于算计比掌握知识更加重要。
然而,在过去的几个月里,有一些非常令人吃惊的结果需要我们了解。深度思维公司对围棋的兴趣并没有随着比赛的胜利而结束。你可能会问,此后还有什么要做的吗?不满足于3∶0的比分,要以20∶0取胜?不,当然不是。超级围棋程序已经成为一种内部的试金石。它的标准是无争议的,已被量化,如果有人想要测试一个新的自我学习的人工智能程序及其性能,可以把它同AlphaGo程序进行比较分析。
一个叫做AlphaZero的新型人工智能诞生了。它有几个截然不同的变化。首先,AlphaGo显示了成千上万的专家级游戏案例可供其自我学习,而AlphaZero却没有显示任何游戏案例――连一个也没有。它只是学了规则,而没有其他任何信息。结果却令人颇为震惊。在短短3天内,AlphaZero完全自学的围棋程序比那个打败了李世石的程序版本更强大,这是此前的人工智能需要一年的时间才能实现的。在3周内,AlphaZero战胜了之前打败柯洁的最强大的AlphaGo版本。还值得注意的是,击败李世石的程序版本使用了48个高度专业化的处理器来创建程序,但AlphaZero只使用了4个。
AlphaZero学习国棋象棋
尽管深度思维公司已经展示了围棋方面接近革命性的突破,实际上国际象棋20年前已经有了突破进展。国际象棋已经有了人工智能“深蓝”(1997年俄罗斯国际象棋特级大师加里?卡斯帕罗夫与IBM公司研发的超级计算机深蓝进行了对决,深蓝最终的胜出表明人类最强国际象棋大师已经彻底被人工智能所击败)。如今,即使是一部高性能的智能手机也能打败国际象棋世界冠军。那么究竟还需要证明什么呢?
值得一提的是,深度思维的创始人丹米斯·哈撒比斯(Demis Hassabis)本人同国际象棋有着深厚的渊源。青少年时代的他就是一个国际象棋神童――当时世界上14岁以下的国际象棋选手中,13岁的哈撒比斯,仅次于尤迪特·波尔加(Judit Polgar),位列第二。他最终离开了国际象棋领域去追求其他的梦想,比如他在17岁时创建了自己的个人电脑视频游戏公司,但他对国际象棋的兴趣始终都在。每个人的脑海中仍然有一个亟待解决的问题:如果让AlphaZero学习国际象棋,会有怎样的表现呢?它也许很智能,但是否会被如今的数据处理引擎所打败呢?或者会有一些特别的事情发生吗?

国际象棋特级大师加里·卡斯帕罗夫与深度思维的创始人丹米斯·哈撒比斯在聊天
一个新范式
《精通国际象棋和将棋――用一种常规的强化学习算法实现自主学习》

本文认为,AlphaZero 通过使用其深层神经网络补偿其分析案例较少的问题,从而更有选择性地专注于最有价值的分析――可以说是一种更接近于人类的思考方式。正如信息论创始人克劳德·香农(Claude Elwood Shannon)最初提出的那样。
2017年12月5日,深度思维研究团队在康奈尔大学的网站上发表了一篇论文,名为《精通国际象棋和将棋――用一种常规的强化学习算法实现自主学习》,结果令人相当震惊。AlphaZero不仅仅做到了对游戏的掌握,而且在很多方面达到了新的高度――这被认为不可思议的。当然,一切还得靠实际测试来证明,所以在深入讨论一些令人颇感兴趣的关键性细节之前,让我们先看看AlphaZero的战绩吧!它与最新及最强大版的Stockfish国际象棋引擎进行了一场比赛,并以64∶36的惊人比分获胜,不仅如此,AlphaZero甚至没有一场负局(28胜,72平)。
对于《国际象棋数据库》软件的使用者来说,Stockfish就无须介绍了。但值得注意的是,Stockfish在一台计算机上的运行速度比AlphaZero快了900倍!实际上,AlphaZero每秒大约计算8万个位置,而Stockfish如果运行在一台64线程(可能是32核)的个人电脑上,每秒运行7 000万个位置。为了更好地理解这一差距究竟有多大,可以这样理解――如果Stockfish另一版本的运行速度慢了900倍,就相当于减少了大约8步棋。这怎么可能呢?
换句话说,AlphaZero不是用一种混合的强力攻击方法――当今国际象棋引擎的核心,而是以一种截然不同的方法,使用了一种非常有选择性的搜索,可以模拟人类的思维方式。一个顶尖的选手可以在一致性和深度方面超过一个能力较弱的选手,但即使是顶尖选手,也无法与哪怕是最弱的计算机程序所做的相提并论。人类完全是通过自己的知识和能力,才能够过滤掉很多步骤,以使自己能够达到某种水平。值得一提的是,尽管加里?卡斯帕罗夫输给了人工智能“深蓝”,但还完全不清楚的是,在当时“深蓝”是否真的比卡斯帕罗夫更强大,尽管其速度已达到了每秒2亿个位置。虽然AlphaZero比Stockfish的运行速度慢了900倍,但如果AlphaZero真的能够利用它的理解能力对此进行弥补,进而超越Stockfish,那么我们将看到一个重大的范式变化。
AlphaZero 的思考时间越长,它的表现就越好
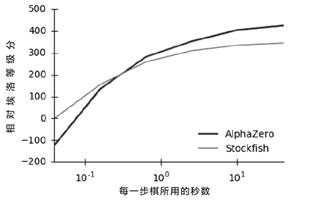
以一个相对埃洛等级分值来衡量(相当于Stockfish 的40 毫秒思考时间),该图显示了每一个玩家在不同时间上的埃洛等级分值。AlphaZero 的蒙特卡洛树搜索(MCTS)在同样的思考时间内效率比Stockfish 都更高,这不禁让人们开始质疑一个原来普遍认可的观念――alpha-beta 搜索在这些领域具有内在的优势
AlphaZero如何下棋?
由于AlphaZero并没有从任何国际象棋知识中受益,意味着没有游戏或开局理论,也意味着它必须自己去发现开局理论。回想一下,开头我们就说到这是AlphaZero进行了仅仅24小时自主学习的结果。研究团队制作了令人颇感兴趣的图表,展示了AlphaZero自己发现的开局理论,以及随着它变得越来越强大而逐渐放弃的那些开局理论。
上述论文的发表还伴随着十场比赛的结束。需要说明的是,这些与一般的引擎游戏是迥然不同的。曾经获得国际象棋世界冠军的卡尔波夫(Karpov)如果是一个国际象棋引擎,他可能被称为AlphaZero。有一种毫不留情的“大蟒蛇”位置分析方法,是闻所未闻的。现代的国际象棋引擎专注于活动,因为它们对活动本身并不理解,需要设有特别的保护措施,以避免因对手组合攻击而卡壳――它们往往还没意识到就发现自己已经走入一个死胡同了。AlphaZero则不存在这样的问题,而且似乎很擅长对付对方的组合布局。这让人印象深刻,令人惊讶的是,它还能找到国际象棋引擎似乎无视的战术。
展望未来
那么这一切对于国际象棋来说有什么意义呢?这是一个“游戏规则改变者”――一个经常被使用、甚至滥用的术语,没有其他的方式来描述它。人工智能“深蓝”是一个突破性的事件,但它的结果却是得益于高度专业化的硬件――目前只在国际象棋方面有所应用。例如,如果有人试图让它下围棋,是永远不可能的。而AlphaZero这种完全开放式的人工智能则可以从最少的信息量中学习,并达到迄今为止最高的水平。这并非一种威胁――在大量的活动中击败我们,而是一种希望――分析诸如疾病、饥荒等问题,以期找到真正的解决方案。
资料来源 Wired
责任编辑 游溪